centos7+hadoop完全分布式集群搭建
Hadoop集群部署,就是以Cluster mode方式进行部署。本文是基于JDK1.7.0_79,hadoop2.7.5。
1.Hadoop的节点构成如下:
HDFS daemon: NameNode, SecondaryNameNode, DataNode
YARN damones: ResourceManager, NodeManager, WebAppProxy
MapReduce Job History Server
本次测试的分布式环境为:Master 1台 (test166),Slave 1台(test167)
2.1 安装JDK及下载解压hadoop
JDK安装可参考:https://www.cnblogs.com/Dylansuns/p/6974272.html 或者简单安装:https://www.cnblogs.com/shihaiming/p/5809553.html
从官网下载Hadoop最新版2.7.5
- http:
将hadoop解压到/usr/hadoop/下
[hadoop@hadoop-master ~]$ tar zxvf /root/hadoop-2.7.5.tar.gz
结果:

[hadoop@hadoop-master ~]$ ll total 211852 drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Desktop drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Documents drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Downloads drwxr-xr-x. 10 hadoop hadoop 4096 Feb 22 01:36 hadoop-2.7.5 -rw-rw-r--. 1 hadoop hadoop 216929574 Dec 16 12:03 hadoop-2.7.5.tar.gz drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Music drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Pictures drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Public drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Templates drwxr-xr-x. 2 hadoop hadoop 6 Jan 31 23:41 Videos [hadoop@hadoop-master ~]$
2.2 在各节点上设置主机名及创建hadoop组和用户
所有节点(master,slave)
1 [root@hadoop-master ~]# su - root 2 [root@hadoop-master ~]# vi /etc/hosts 3 10.86.255.166 hadoop-master 4 10.86.255.167 slave1 5 注意:修改hosts中,是立即生效的,无需source或者. 。
先使用
建立hadoop用户组
新建用户,useradd -d /usr/hadoop -g hadoop -m hadoop (新建用户hadoop指定用户主目录/usr/hadoop 及所属组hadoop)
passwd hadoop 设置hadoop密码(这里设置密码为hadoop)
groupadd hadoop
2.3 在各节点上设置SSH无密码登录
最终达到目的:即在master:节点执行 ssh hadoop@salve1不需要密码,此处只需配置master访问slave1免密。
su - hadoop
进入~/.ssh目录
执行:ssh-keygen -t rsa,一路回车
生成两个文件,一个私钥,一个公钥,在master1中执行:cp id_rsa.pub authorized_keys
[hadoop@hadoop-master ~]$ su - hadoop [hadoop@hadoop-master ~]$ /usr/-master ~]$ cd .-master .]$ -/ to save the key (/usr/hadoop/./ /usr/hadoop/./ /usr/hadoop/./:b2::8c:e7::1d:4c:2f:::1a:::bb:de hadoop@hadoop- +--[ RSA ]----+ |=+*.. . . | |oo O . o . | |. o B + . | | = + . . | | + o S | | . + | | . E | | | | | +-----------------+-master .]$ [hadoop@hadoop-master . cp id_rsa.pub authorized_keys
2.3.1:本机无密钥登录
[hadoop@hadoop-master ~]$ -R .
验证:
没有提示输入密码则表示本机无密钥登录成功,如果此步不成功,后续启动hdfs脚本会要求输入密码
[hadoop@hadoop-master ~]$ ssh hadoop@hadoop-master Last login: Fri Feb 23 18:54:59 2018 from hadoop-master [hadoop@hadoop-master ~]$
2.3.2:master与其他节点无密钥登录
( 若已有authorized_keys,则执行ssh-copy-id ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave1 上面命令的功能ssh-copy-id将pub值写入远程机器的~/.ssh/authorized_key中
)
从master中把authorized_keys分发到各个结点上(会提示输入密码,输入slave1相应的密码即可):
/usr/hadoop/./authorized_keys hadoop@slave1:/home/master/.
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop@slave1'" and check to make sure that only the key(s) you wanted were added.
[hadoop@hadoop-master .ssh]$
然后在各个节点对authorized_keys执行(一定要执行该步,否则会报错):chmod 600 authorized_keys
保证.ssh 700,.ssh/authorized_keys 600权限
测试如下(第一次ssh时会提示输入yes/no,输入yes即可):
[hadoop@ ~]$ : Fri Feb :: ~]$
2.4 设置Hadoop的环境变量
Master及slave1都需操作
[root@hadoop-master ~]# su - root [root@hadoop-master ~]# vi /etc/profile 末尾添加,保证任何路径下可执行hadoop命令 JAVA_HOME=/usr/java/jdk1.7.0_79 CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=/usr/hadoop/hadoop-2.7.5/bin:$JAVA_HOME/bin:$PATH
让设置生效
[root@hadoop-master ~]# source /etc/profile 或者 [root@hadoop-master ~]# . /etc/profile
Master设置hadoop环境
# etc/hadoop/hadoop-.export JAVA_HOME=/usr/java/jdk1. export HADOOP_HOME=/usr/hadoop/hadoop-.
此时hadoop安装已完成,可执行hadoop命令,后续步骤为集群部署
[hadoop@hadoop-master ~]$ hadoop Usage: hadoop [--config confdir] [COMMAND | CLASSNAME] CLASSNAME run the class named CLASSNAME or where COMMAND is one of: fs run a generic filesystem user client version print the version jar <jar> run a jar file note: please use "yarn jar" to launch YARN applications, not this command. checknative [-a|-h] check native hadoop and compression libraries availability distcp <srcurl> <desturl> copy file or directories recursively archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive classpath prints the class path needed to get the credential interact with credential providers Hadoop jar and the required libraries daemonlog get/set the log level for each daemon trace view and modify Hadoop tracing settings Most commands print help when invoked w/o parameters. [hadoop@hadoop-master ~]$
2.5 Hadoop设定
2.5.0 开放端口50070
注:centos7版本对防火墙进行 加强,不再使用原来的iptables,启用firewall
Master节点:
su - root firewall-cmd --state 查看状态(若关闭,则先开启systemctl start firewalld) firewall-cmd --list-ports 查看已开放的端口 开启8000端口:firewall-cmd --zone=public(作用域) --add-port=8000/tcp(端口和访问类型) --permanent(永久生效) firewall-cmd --zone=public --add-port=1521/tcp --permanent firewall-cmd --zone=public --add-port=3306/tcp --permanent firewall-cmd --zone=public --add-port=50070/tcp --permanent firewall-cmd --zone=public --add-port=8088/tcp --permanent firewall-cmd --zone=public --add-port=19888/tcp --permanent firewall-cmd --zone=public --add-port=9000/tcp --permanent firewall-cmd --zone=public --add-port=9001/tcp --permanent firewall-cmd --reload -重启防火墙 firewall-cmd --list-ports 查看已开放的端口 systemctl stop firewalld.service停止防火墙 systemctl disable firewalld.service禁止防火墙开机启动 关闭端口:firewall-cmd --zone= public --remove-port=8000/tcp --permanent
Slave1节点:
su - root
systemctl stop firewalld.service停止防火墙 systemctl disable firewalld.service禁止防火墙开机启动
2.5.1 在Master节点的设定文件中指定Slave节点
[hadoop@hadoop-master hadoop]$ pwd /usr/hadoop/hadoop-2.7.5/etc/hadoop [hadoop@hadoop-master hadoop]$ vi slaves slave1
2.5.2 在各节点指定HDFS文件存储的位置(默认是/tmp)
Master节点: namenode
创建目录并赋予权限
Su - root # mkdir -p /usr/local/hadoop-2.7.5/tmp/dfs/name # chmod -R 777 /usr/local/hadoop-2.7.5/tmp # chown -R hadoop:hadoop /usr/local/hadoop-2.7.5
Slave节点:datanode
创建目录并赋予权限,改变所有者
Su - root # mkdir -p /usr/local/hadoop-2.7.5/tmp/dfs/data # chmod -R 777 /usr/local/hadoop-2.7.5/tmp # chown -R hadoop:hadoop /usr/local/hadoop-2.7.5
2.5.3 在Master中设置配置文件(包括yarn)
# etc/hadoop/core- <configuration> <property> <name>fs.default.name</name> <value>hdfs: </property> <property> <name>hadoop.tmp.</name> <value>/usr/local/hadoop-./tmp</value> </property> </configuration>
1 # vi etc/hadoop/hdfs-site.xml 2 3 <configuration> 4 5 <property> 6 7 <name>dfs.replication</name> 8 9 <value>3</value> 10 11 </property> 12 13 <property> 14 15 <name>dfs.name.dir</name> 16 17 <value>/usr/local/hadoop-2.7.5/tmp/dfs/name</value> 18 19 </property> 20 21 <property> 22 23 <name>dfs.data.dir</name> 24 25 <value>/usr/local/hadoop-2.7.5/tmp/dfs/data</value> 26 27 </property> 28 29 30 31 </configuration>
1 #cp mapred-site.xml.template mapred-site.xml 2 3 # vi etc/hadoop/mapred-site.xml 4 5 <configuration> 6 7 <property> 8 9 <name>mapreduce.framework.name</name> 10 11 <value>yarn</value> 12 13 </property> 14 15 </configuration>
YARN设定
yarn的组成(Master节点: resourcemanager ,Slave节点: nodemanager)
以下仅在master操作,后面步骤会统一分发至salve1。
1 # vi etc/hadoop/yarn-site.xml 2 3 <configuration> 4 5 <property> 6 7 <name>yarn.resourcemanager.hostname</name> 8 9 <value>hadoop-master</value> 10 11 </property> 12 13 <property> 14 15 <name>yarn.nodemanager.aux-services</name> 16 17 <value>mapreduce_shuffle</value> 18 19 </property> 20 21 </configuration>
2.5.4将Master的文件分发至slave1节点。
cd /usr/hadoop scp -r hadoop-2.7.5 hadoop@hadoop-master:/usr/hadoop
2.5.5 Master上启动job history server,Slave节点上指定
此步2.5.5可跳过
Mater:
启动jobhistory daemon
# sbin/mr-jobhistory-daemon.sh start historyserver
确认
# jps
访问Job History Server的web页面
http://localhost:19888/
Slave节点:
1 # vi etc/hadoop/mapred-site.xml 2 3 <property> 4 5 <name>mapreduce.jobhistory.address</name> 6 7 <value>hadoop-master:10020</value> 8 9 </property>
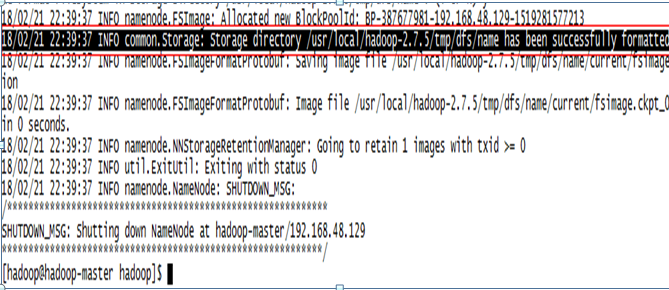
2.5.6 格式化HDFS(Master)
# hadoop namenode -format
Master结果:
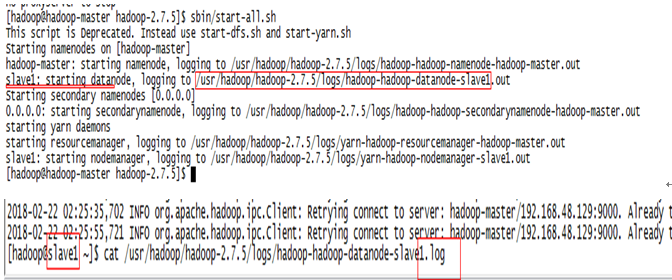
2.5.7 在Master上启动daemon,Slave上的服务会一起启动
启动:
[hadoop@hadoop-master hadoop-2.7.5]$ pwd /usr/hadoop/hadoop-2.7.5[hadoop@hadoop-master hadoop-2.7.5]$ sbin/start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [hadoop-master] hadoop-master: starting namenode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop-master.out slave1: starting datanode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-hadoop-datanode-slave1.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.7.5/logs/hadoop-hadoop-secondarynamenode-hadoop-master.out starting yarn daemons starting resourcemanager, logging to /usr/hadoop/hadoop-2.7.5/logs/yarn-hadoop-resourcemanager-hadoop-master.out slave1: starting nodemanager, logging to /usr/hadoop/hadoop-2.7.5/logs/yarn-hadoop-nodemanager-slave1.out [hadoop@hadoop-master hadoop-2.7.5]$
确认
Master节点:
[hadoop@hadoop-master hadoop-2.7.5]$ jps 81209 NameNode 81516 SecondaryNameNode 82052 Jps 81744 ResourceManager
Slave节点:
[hadoop@slave1 ~]$ jps 58913 NodeManager 59358 Jps 58707 DataNode
停止(需要的时候再停止,后续步骤需running状态):
[hadoop@hadoop-master hadoop-2.7.5]$ sbin/stop-all.sh This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh Stopping namenodes on [hadoop-master] hadoop-master: stopping namenode slave1: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: stopping secondarynamenode stopping yarn daemons stopping resourcemanager slave1: stopping nodemanager no proxyserver to stop
2.5.8 创建HDFS
# hdfs dfs -mkdir /user # hdfs dfs -mkdir /user/test22
2.5.9 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop/*.sh /user/test22/input
查看
# hdfs dfs -ls /user/test22/input
2.5.10 执行hadoop job
统计单词的例子,此时的output是hdfs中的目录,hdfs dfs -ls可查看
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /user/test22/input output
确认执行结果
# hdfs dfs -cat output/*
2.5.11 查看错误日志
注:日志在salve1的*.log中而不是在master或*.out中
2.6 Q&A
1. hdfs dfs -put 报错如下,解决关闭master&salve防火墙
hdfs.DFSClient: Exception in createBlockOutputStream
java.net.NoRouteToHostException: No route to host
转自:https://www.cnblogs.com/pu20065226/p/8464156.html
来自ansion博客
2019-09-03 16:16:40

